
Today, we will unveil a new generation of speech recognition systems from Science and Technology News for everyone.
As we all know, since 2011, Microsoft Research has used the Deep Neural Network (DNN) for the first time to achieve significant improvements in large-scale speech recognition tasks. DNN has received more and more attention in the field of speech recognition and has become mainstream. Standard for speech recognition systems. However, more in-depth research results show that although the DNN structure has strong classification ability, its ability to capture context timing information is weak, so it is not suitable for processing timing signals with long-term correlation. Voice is a complex time-varying signal with strong correlation between frames. This correlation is mainly reflected in the phenomenon of coordinated pronunciation when speaking. Usually several words have influence on the words we are talking about. That is, there is a long-term correlation between frames of speech.
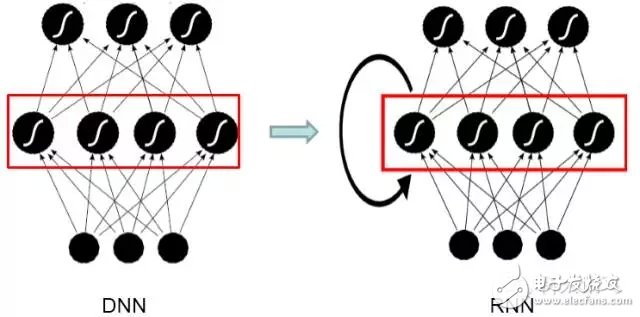
Figure 1: Schematic diagram of DNN and RNN
Compared with the feedforward neural network DNN, the Recurrent Neural Network (RNN) adds a feedback connection to the hidden layer. That is to say, the input of the current moment of the RNN hidden layer is a hidden layer output of the previous moment. This allows the RNN to see the information at all times before through the loop feedback connection, which gives the RNN memory function, as shown in Figure 1. These features make RNN very suitable for modeling timing signals. In the field of speech recognition, RNN is a new deep learning framework to replace DNN in recent years, and the introduction of Long-Short Term Memory (LSTM). The problem of the disappearance of the traditional simple RNN gradient is solved, and the RNN framework can be put into practical use in the field of speech recognition and obtained the effect of surpassing DNN. It has been used in some advanced speech systems in the industry.
In addition, the researchers have made further improvements on the basis of RNN. Figure 2 is the mainstream RNN acoustic model framework for speech recognition. It mainly consists of two parts: deep bidirectional LSTM RNN and CTC (ConnecTIonist Temporal ClassificaTIon). Output layer. When the bidirectional RNN judges the current speech frame, not only the historical speech information but also the future speech information can be utilized, and more accurate decision can be made; the CTC makes the training process not require frame level annotation, and implements an effective “end pairâ€. End training.
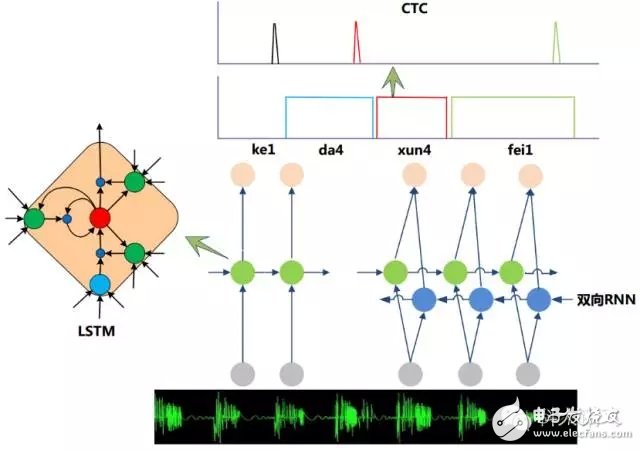
Figure 2: Mainstream acoustic model framework based on LSTM RNN
At present, many academic or industrial institutions in the world have mastered the RNN model and conducted research at one or more of the above technical points. However, the above technical points can generally obtain better results when studied separately, but if you want to integrate these technical points together, you will encounter some problems. For example, the combination of multiple technologies will increase by a smaller amount than the sum of the individual technology points. For another example, the traditional two-way RNN scheme theoretically needs to see the end of speech (that is, all future information) in order to successfully apply future information for promotion, so it is only suitable for offline tasks, but for online tasks that require immediate response. (such as voice input method) will often bring a hard delay of 3-5s, which is unacceptable for online tasks. Furthermore, the RNN fits the context correlation more strongly, and it is more likely to fall into the over-fitting problem than the DNN. It is easy to bring additional anomaly recognition errors due to the local non-robustness of the training data. Finally, because RNN has a more complex structure than DNN, it brings more challenges to the training of RNN models under massive data.
In view of the above problems, HKUST has invented a new framework called Feed-forward Sequen TIal Memory Network (FSMN). In this framework, the above points can be well integrated, and the improvement of the effect of each technology point can be superimposed. It is worth mentioning that the FSMN structure that we creatively proposed in this system uses a non-cyclic feedforward structure, which achieves the same effect as the bidirectional LSTM RNN with only 180ms delay. Let us take a closer look at its composition.
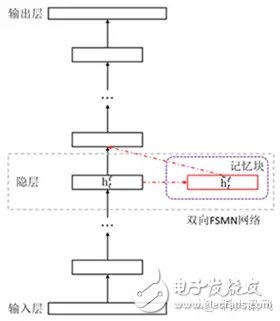
Figure 3: Schematic diagram of FSMN structure
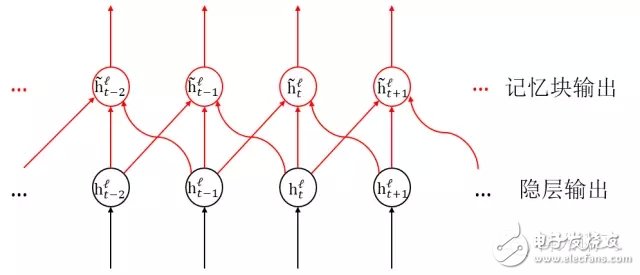
Figure 4: Schematic diagram of the timing of the hidden layer memory block in FSMN (one frame left and right)
Figure 3 is a schematic diagram of the structure of the FSMN. Compared with the traditional DNN, we add a module called "memory block" next to the hidden layer for storing historical information and future information useful for judging the current speech frame. Figure 4 shows the timing structure of the memory information in the two-way FSMN in the memory block (in the actual task, the history of the required memory and the length of the future information can be manually adjusted according to the task).
As can be seen from the figure, unlike the traditional loop feedback based RNN, the memory function of the FSMN memory block is implemented using a feedforward structure. This feedforward structure has two major advantages: First, when the bidirectional FSMN remembers future information, there is no limitation that the traditional bidirectional RNN must wait for the end of the speech input to judge the current speech frame. It only needs to wait for a finite length of future speech frame. That is, as mentioned above, our two-way FSMN can achieve the effect of a two-way RNN with a delay of 180ms. Secondly, as mentioned above, the traditional simple RNN is pressed because of the gradient during training. Time passes forward one by one, so there is an exponentially decaying gradient disappearance, which leads to the fact that the theoretically infinitely long memory RNN can actually remember very limited information. However, FSMN is a memory network based on feedforward timing expansion structure. During the training process, the gradient is transmitted back to each moment along the connection weights of the memory block and the hidden layer in FIG. 4, and these connection weights determine the influence of the input at different times on judging the current speech frame, and the gradient propagation is The attenuation at any time is constant and trainable, so FSMN solves the problem in RNN in a simpler way. Of disappearing, so that it has long-term memory capacity of similar LSTM.
In addition, in terms of model training efficiency and stability, since FSMN is completely based on feedforward neural network, there is no case of wasted operation in RNN training due to the need to fill zeros in mini-batch. The feedforward structure also makes It has a higher degree of parallelism and maximizes the power of GPU computing. From the distribution of weighted coefficients at each moment in the two-way FSMN model memory block that is finally trained to converge, we observe that the weight value is basically the largest at the current time and gradually decays to the left and right sides, which is also in line with expectations. Further, FSMN can be combined with CTC guidelines to achieve "end-to-end" modeling in speech recognition.
Finally, combined with other technical points, Xunfei's FSMN-based speech recognition framework can achieve 40% performance improvement over the industry's best speech recognition system, combined with our multi-GPU parallel acceleration technology, training efficiency can be achieved Ten thousand hours of training data can be trained to converge on a day. Subsequent based on the FSMN framework, we will also carry out more related research work, such as: DNN and deeper combination of memory blocks, increase memory block partial complexity and strengthen memory function, FSMN structure and CNN and other structures for deeper integration. . Based on the continuous improvement of these core technologies, the speech recognition system of HKUST will continue to challenge new peaks!
Fasteners, fastened and used for a very wide range of applications and a type of mechanical parts. Fasteners, the use of a wide range of industries, including energy, electronics, electrical, mechanical, chemical, metallurgy, mold, hydraulic and so on, in a variety of machinery, equipment, vehicles, ships, railways, bridges, construction, structure, tools, equipment , Chemicals, instruments and supplies above, you can see all kinds of fasteners, is the most widely used mechanical basis. It is characterized by a wide variety of specifications, performance, use different, but also standardization, serialization, the degree of generalization is also very high.
Type: Lock nuts and Tools
Size: M10 and M12
Material: Carbon steel
Finishing: Zinc coated
Application: Kinds of lines which need bolts and nuts, this nuts can not be screwed by normal tools, it can avoid losses for you.

Fasteners Series,Lock Nuts And Tools,Fastener Lock Nuts,Steel Lock Nuts
HEBEI ZIFENG NEW ENERGY TECHNOLOGY CO.,LTD. , https://www.zifengpipeline.com