
At the 3rd World Internet Conference Wuzhen Summit, Sogou’s live speech “performance†at the conference attracted people’s attention. On November 21st, Sogou officially launched this real-time translation technology based on the voice interaction engine "Knowledge".
According to reports, Sogou voice real-time translation technology is Sogou self-developed machine simultaneous interpretation technology. Based on big data and deep learning, this technology covers Sogou's self-developed two important technologies of speech recognition and machine translation. Its accuracy rate can reach 97%, support high-speed dictation of 400 words per second, and voice input can be as high as daily. 190 million times.
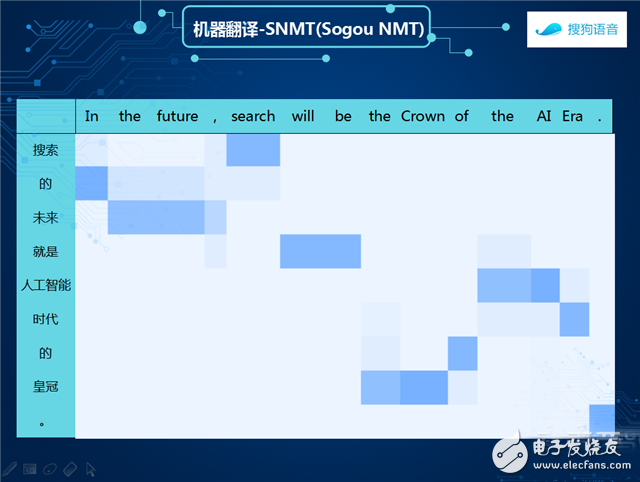
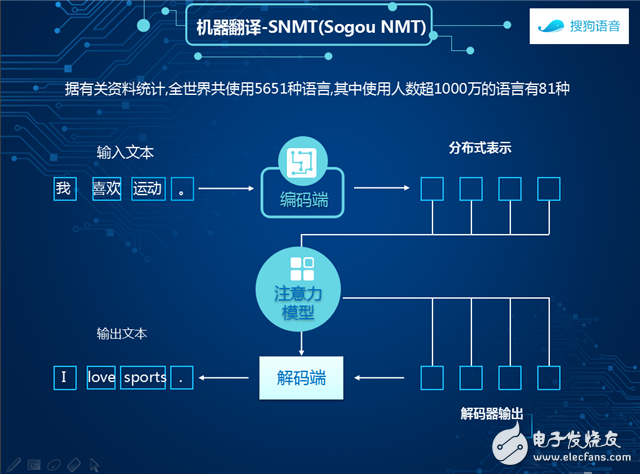
Sogou machine translation fusion end-to-end neural machine translation technology and instance-based translation technology, using the end-to-end neural network translation model to obtain a distributed representation of the source sentence through the encoding end, using the attention model to focus the source, using the circulating nerve The network generates translation results.
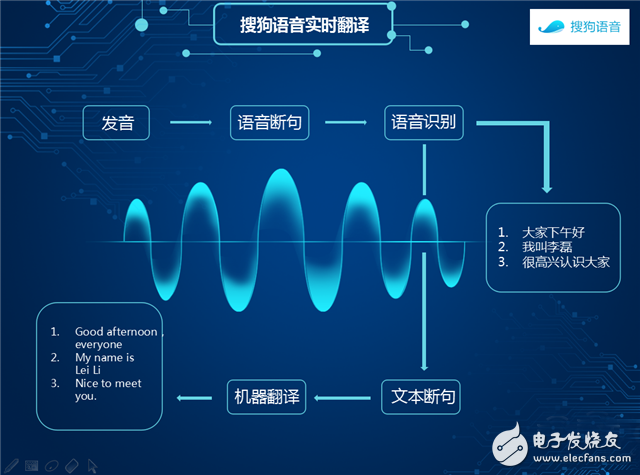
In Sogou's entire translation system, the first system functions as a phonetic sentence. When receiving a particularly long speech signal, the system automatically determines the mute and effective tones through machine learning; speech (1) and non-speech (0). There are two methods for judging. The first is based on the method of energy detection. The energy is small and the energy is very large. The second is based on the judgment of the deep learning model. Through a large amount of data modeling, after modeling. It can be automatically detected by the model. When it is detected that the probability that this place belongs to non-speech is higher, the system considers it to be non-speech, and when the probability of speech is high, it is judged as speech.
The second system function is speech recognition, which is designed to convert speech signals into text. The mapping between speech and text is described by a probabilistic target that wishes to give the current speech signal, maximize the probability of output W, and output the corresponding W difference as the optimal speech recognition result.
In the overall framework of speech recognition, two very important models are involved. One is the acoustic model, which is the similarity between the model and the sound signal when people pronounce each unit. The other is the language model, which describes the recognition. The possibility of a connection between words and words in the result, thus better standardizing the overall output, more fluent and smooth.
The whole translation operation structure is like this. The first part is the technology of the encoding end. Based on the neural network technology, the system records the collected speech signals into an encoder. The encoder has a language translation function, which can extract the feature sentences in the speech and translate them. Into the whole sentence. After that, the model is entered into the alignment model. The model determines which words and which words can be associated with each other, and contributes the characteristics of these words to the decoding end to obtain the text, which serves as an end-to-end mapping effect.
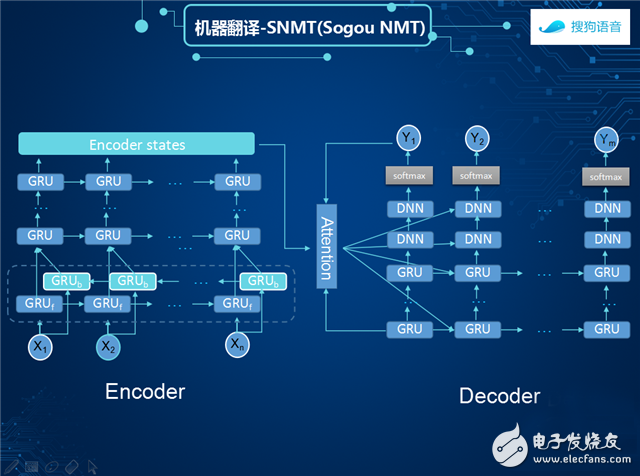
The second part is Decoder technology. From the actual evaluation of accuracy, the structure of GRU will be lighter and the operation speed is faster. In the current simultaneous transmission technology, Sogou uses the two-way GRU technology to construct the structure of the coding end. The decoding end is abstracted and then connected to the output of Softmax. This is the running process of the entire Sogou real-time translation.
Sogou voice real-time translation technology can effectively combine speech recognition and machine translation. In the future, on the road of technology change life, we hope that more voice translation software can optimize the performance and effect of real-time voice translation, and continue to bring more perfect and practical voice technology and products to users, and promote the entire voice industry and even labor. Technological innovation and advancement in the field of intelligence.
Retro Speaker,Bluetooth Retro Speaker,Rechargeable Retro Speaker,Portable Retro Speaker
Shenzhen Focras Technology Co.,Ltd , https://www.focras.com