
The demand for digital video products has soared in recent years. Mainstream applications include video communications, video surveillance and industrial automation, while the most popular are entertainment applications such as DVD, HDTV, satellite TV, standard definition (SD) or high definition (HD) set-top boxes, digital cameras and HD camcorders, high-end displays (LCD). , plasma display, DLP) and personal video cameras. These applications have placed great demands on high-quality video codec algorithms and their standards. Currently, the mainstream compression standards mainly include MPEG2, MPEG4, and H.264/AVC, and there are various implementation solutions for these codec standards. This paper mainly discusses several factors that need to be considered in the standard system optimization process of video decoding algorithms based on TI's C64 series DSP.
TI's C64 series DSPs are widely used in the video processing field because of their powerful processing capabilities. However, due to the different understanding of the structure, instructions, and understanding of the C64 series DSPs, there are many differences in the effects of the algorithm implementation. It is embodied in the resources of the CPU used to implement the algorithm. For example, when implementing H.264 MP@D1 decoding, the CPU resources may be different, or it may be included in the subset of algorithm tools, such as CAVLC instead of CABAC when implementing H.264 MP@D1 decoding. The main reasons for these differences are the following: optimization of key modules of the algorithm
Memory management when algorithm system integration
Resource Allocation Management of EDMA in Algorithm System Integration
This paper gradually discusses several factors that need to be considered in algorithm optimization integration from these three aspects. Optimization of key modules of the algorithm Generally speaking, for the current mainstream video decompression standards, there are similar modules that consume DSP CPU. For example, motion vector search in H.264/AVC, MPEG4, AVS, etc. is very resource-intensive, and these modules Calling is quite frequent throughout the system implementation, so we first find out these modules. This point, TI's CCS provides a project analysis tool (Profile), which can quickly find the modules that occupy the most DSP CPU resources in the entire project; The module is optimized.
The optimization of these key algorithm modules can be divided into three steps, as shown in Figure 2, first carefully analyze this part of the code, and make corresponding adjustments, such as minimize the code with judgment jumps, especially in the for loop. Judging a jump will interrupt the software flow. The method used is to use a look-up table or use Intrinsics such as _cmpgtu4 and _cmpeq4 instead of the comparison judgment instruction, thereby subtly replacing the judgment jump statement. At the same time, using #pragma provided in TI's CCS provides as much information as possible to the compiler, including information on the number of times for the for loop, data alignment information, and so on. If this part of the optimization can not meet the system requirements, then this part of the module uses linear assembly implementation, linear assembly is a language implementation between C and assembly, you can control the use of instructions, without special attention to registers, functions The allocation and use of cells (S, D, M, L), using linear assembly is generally more efficient than using C language. If the linear assembly can not meet the requirements, then use the assembly implementation, to write a high-parallel, deep software pipeline assembly needs to draw the relevant diagram, create a scheduling table (Scheduling table) and other steps, due to space limitations, here is not described . 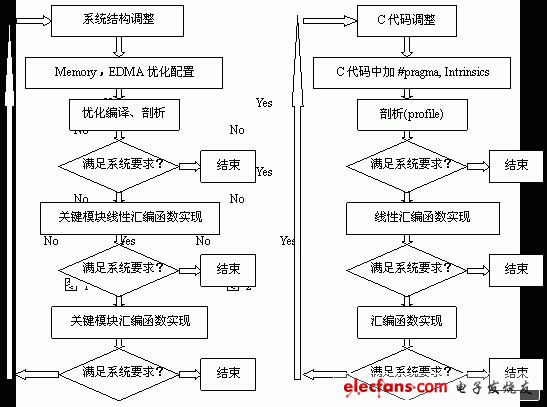
Table 1 Number of usage cycles
C+Intrinsics83
Linear assembly 74
Compilation 57
Optimization options: -pm, -o3, based on the C64plus kernel, C+Instrinsics refers to the use of Instrinsics in C.
Table 1 shows the number of cycles of the DSP CPU consumed in different modes when calculating the 16×16 macroblock SAD value required for motion search. It can be seen that the assembly implementation consumes the least number of CPU cycles, but the premise is that you need to fully understand the structure of the DSP CPU, the instructions, and the structure of the algorithm module, so that you can write a high-parallel, deep software pipeline assembly, otherwise it is possible The compiled assembly is not yet linearly compiled or C is more efficient. An effective method for this is to make full use of the functions in the algorithm library provided by TI, because the functions in the algorithm library are fully optimized algorithm modules, and most of them provide corresponding C, linear assembly and assembly. Source code, and documentation for API introduction. Memory management during algorithm system integration Because in the development of DSP-based embedded systems, storage resources, especially on-chip high-speed storage resources are limited, Memory management is very important to improve the optimization of the entire system when the algorithm is integrated. Aspects affect the reading and moving speed of data; on the other hand, it also affects the hit rate of Cache. The following sections analyze the program and data.
Program area: The biggest principle is to put the algorithm modules that are frequently scheduled for use in the film. To do this, TI's CCS provides #pragma CODE_SECTION, which separates the function segments that need to be controlled separately from the .text section, so that these function segments are mapped separately in the .cmd file. You can also use the program dynamic method to schedule the code segments that need to be run into the on-chip memory. For example, the two algorithm modules CAVLC and CABAC in H.264/AVC are mutually exclusive, so you can put these two algorithm modules on each other. Off-chip and corresponding to the same running area on the chip, before running one of the algorithm modules, first transfer it into the chip, so as to make full use of the limited high-speed storage area on the chip. The management of the program area takes into account the hit rate of the first-level program Cache (L1 P). It is better to configure the functions with sequential execution order in the program space in the order of addresses, and split the processing functions with larger code. Small function.
Data area: In the video standard codec, since the data blocks are large, such as a frame D1 4:2:0 image has a size of 622k, and in the codec need to open 3~5 frames or even more buffer frames, Therefore, the data is basically not stored on the chip. For this reason, in the memory optimization management of the system, it is necessary to open the secondary cache of the C64 series DSP (for the TMS320DM642 for the video codec, the secondary cache is open 64k). At the same time, it is better to align the data of the video buffer mapped by the Cache outside the slice by 128 bytes. This is because the size of each line of the secondary cache of the C64 series DSP is 128 bytes, and the 128 byte alignment is beneficial to the Cache. Refresh and consistency maintenance. EDMA resource allocation management during algorithm system integration Because there is often block data moving in video processing, and C64 series DSP provides EDMA, there are 64 channels logically, so the configuration of EDMA is very important for optimizing the system. important. To do this, you can use the following steps to fully configure the system's EDMA resources. 1. The statistics system needs to use EDMA and the time it takes to occupy the EDMA physical bus, as shown in Table 2:
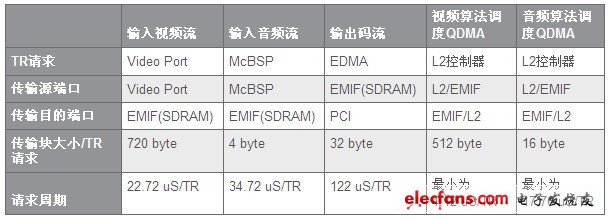
Note: This table is for video via Video Port (720*480, 4:2:0, 30Frame/s), audio is entered into DSP through McBSP (sampling rate is 44k), and the compressed data rate is around 2Mbps. The data outputs a 128-byte packet per PCI 488uS (the PCI port operates at 33MHz), and the external SDRAM clock frequency is 133MHz, which is only a reference application example. 2. After statistics are collected, the priority of each EDMA channel to be used needs to be assigned according to the real-time performance of various code streams and the size of the transmission block. Generally speaking, since the audio stream transmission block is small, the time for occupying the EDMA bus is short, and the video transmission block is relatively large, and the EDMA bus takes a long time. Therefore, the priority of the EDMA channel corresponding to the input audio is set to Q0. (urgent), the priority of the video is set to Q2 (medium), the priority of the EDMA channel corresponding to the output stream is set to Q1 (high), and the priority of the QDMA scheduled in the audio and video algorithm processing is set to Q3 (low). Of course, these settings may need to be adjusted in real system applications. The actual optimization process based on TI DSP video algorithm will be based on the steps shown in Figure 1. First, configure Memory first, and select the corresponding compiler optimization option. If the compiled result can meet the real-time requirements, the subsequent optimization will be ended. Otherwise, optimize the configuration of Memory and EDMA, so as to improve the utilization of Cache and internal bus; if it can not meet the requirements, determine the code segments or functions that consume the most CPU resources by analyzing the whole project, and optimize these key modules with linearity. Assembly, even assembly until the entire system can meet the requirements.
10GbE Media Converters transparently connect 10 Gigabit Ethernet links over multimode or single mode fiber. Each 10G Media Converter comes with pluggable transceiver ports that support fiber to fiber, copper to fiber or copper to copper media conversion.10G media converter are complete and versatile solutions for the application such as FTTx, CWDM and carrier Ethernet. By the diversified speeds of 1,000Mbps and 10G, N-net provides standalone 10G media converter products for different applications and can be applied as per your ideal network topology.
N-net 10G media converter supports various interfaces such as UTP, SFP, SFP+, XFP etc. All these interfaces are developed to support the protocols such as 100Base-Tx, 1000Base-T, 10GBase-T, and 10GBase-LR, 10GBase-SR, which makes your network more complete and solid.
10G Fiber Media Converter,Fiber Optic Media Converter,Fiber Optic Converter,Fiber Media Converter
Shenzhen N-net High-Tech Co.,Ltd , http://www.nnetswitch.com